Příprava XCF souboru pro konverzi do DjVu
Většina dokumentů, které jsou k nalezení na tomto webu – obrázky, DjVu soubory, PDF soubory, atp. – je zpracována pomocí open source nástrojů. Nejde jen o to, že myšlenka open source je woodcraftu z principiálního hlediska blízká. Open source nástroje nabízí v současné době širokou paletu možností při zpracování digitalizovaného obrazu, aniž by bylo nutné platit za užití licencovaných komponent.
V následujícím postupu na konkrétních příkladech demonstruji, jakým způsobem lze připravit soubor, vhodný ke konverzi do DjVu formátu. Formát XCF umožňuje s naskenovaným dokumentem bezpečně pracovat, aniž by při hledání optimálního postupu došlo ke ztrátě obrazové informace.
Jak z tohoto typu souboru získat DjVu dokument tento je popsáno v článku o Zpracování PDF bez textové vrstvy do DjVu souboru s textovou vrstvou
Výchozí sken
Optimální výchozí surovinou pro další zpracování el. dokumentu je plnobarevný sken, s minimální hustotou 300 dpi.
Čím méně dpi a barev, tím méně dostupných informací, na kterých závisí kvalita výsledného produktu.
Více viz článek Digitalizace dokumentů v amatérských podmínkách
Vytvoření XCF souboru
Surové skeny (originály), lze mít uložené jako samostatné obrázky, nebo ve vícestránkových formátech jako je TIFF nebo PDF. Ovšem z hlediska úspory datového prostoru je nejvýhodnější provést jejich archivaci do formátu JPEG-2000.
Pro další zpracování je výhodné naimportovat stránky do XCF dokumentu, což je nativní formát grafického editoru Gimp. Ten umožňuje proces zpracování kdykoli přerušit, dokument uložit a pokračovat v práci později.
Formát XCF není vícestránkový, ale pracuje s vrstvami. Při otevření vícestránkového dokumentu (TIFF, PDF), nebo formátu který pracuje s rámci (MNG, GIF) se naimportují jednotlivé stránky (resp. rámce) jako vrstvy.
Pokud chceme vytvořit vícevrstvý XCF soubor ze samostatných obrázků, je třeba použít z menu volbu Otevřít jako vrstvy a vybrat příslušné obrázky.
Práce s vrstvami významně usnadňuje proces zpracování naskenovaných stránek do podoby vhodné ke konverzi do DjVu formátu. S využitím prolínání vrstev lze vyřešit většinu nedostatků, které vzniknou při skenování.
1, fáze - Nastavení vodítek
První operací, kterou je třeba provést je nastavení vodítek. To lze u GIMPu provést zcela jednoduše "vytažením" vodítek z horní (horizontální vodítko) a postranní (vertikální vodítko) lišty s měřítkem.
Vodítek může být klidně více. Je třeba nastavit je tak, aby vymezovaly oblast do níž se má vejít textový obsah.
 Výchozím bodem pro následující operace s vrstvami bude optimálně zvolený průsečík. Na něj bude mnohem snazší - s ohledem na "přilnavost" vodítek - umísťovat výchozí bod rotace.
Výchozím bodem pro následující operace s vrstvami bude optimálně zvolený průsečík. Na něj bude mnohem snazší - s ohledem na "přilnavost" vodítek - umísťovat výchozí bod rotace.
2, fáze - Duplikace, přejmenování a setřídění vrstev
Každá stránka je zastoupena jednou vrstvou. Pro lepší orientaci, je vhodné změnit pojmenování vrstev tak, aby název vrstvy odpovídal číslu stránky kterou obsahuje.
 Pokud jsou naskenované dvoustránky, je třeba nejprve provést duplikaci takové vrstvy, a každou z nich očíslovat podle stránky, kterou bude po finálním oříznutí obsahovat.
Pokud jsou naskenované dvoustránky, je třeba nejprve provést duplikaci takové vrstvy, a každou z nich očíslovat podle stránky, kterou bude po finálním oříznutí obsahovat.
Při duplikaci a pojmenování vrstev nezáleží na tom zdali jsou vrstvy "zamčeny", nebo ne.
3, fáze - Přesun a rotace vrstvy
Po přejmenování a setřídění vrstev tak aby šly za sebou odshora dolů, můžeme přistoupit k jejich zpracování.
To spočívá především ze dvou následujících operací:
- Přesun
- Je vůbec první nutný krok. Obzvláště, pokud jde o duplikát dvoustrany, kdy je nutné přemístit obsah stránky tak aby se vešel mezi nastavená vodítka.

- Rotace
- Při skenování na plochém skeneru se stává velice často, že jsou stránky naopak - v takovém případě je lepší stránky překlopit tak aby byly správně orientované již při přejmenovávání vrstev. Ovšem jiná situace nastává pokud jsou "pouze" pootočené. V takovém případě je třeba nejprve stránku přesunout tak, aby byl bot rotace optimálně na průsečíku vodítek. Pak můžeme začít s rotací.

- Po volbě transformace vrstvy pootočením o libovolný, předem neznámý úhel, se objeví mřížka, která zabírá celou plochu vrstvy, která má uprostřed bod rotace. Ten lze uchopit a přesunout do průsečíku vodítek, kolem kterého se má vrstva otáčet.

- Teprve poté můžeme přistoupit k rotaci. Stránku natáčíme tak dlouho až je obsah srovnaný. Srovnat jej můžeme buď podle řádku, nebo podle levého či pravého okraje textového bloku. Záleží na obsahu. Někdy je zarovnáván k dolnímu okraji, jindy zase k hornímu. Je to různé.
 Při těchto operacích dávejte pozor, abyste měli aktivní viditelnou vrstvu, která je v zásobníku nejvýš. Abyste se pak nedivili, že se obsah stránky netočí a neposouvá.
Při těchto operacích dávejte pozor, abyste měli aktivní viditelnou vrstvu, která je v zásobníku nejvýš. Abyste se pak nedivili, že se obsah stránky netočí a neposouvá.| Také si hlídejte, aby vrstva se kterou aktuálně pracujete nebyla "zamčená". Zámek ve skutečnosti znamená, že je vrstva svázaná s ostatními "zamčenými" vrstvami. Tzn., že pokud necháte takovou stránku rotovat, budou zároveň natočeny i všechny ostatní svázané stránky. naštěstí lze v takových přípedech operaci vrátit zpět, ovšem obzvláště v případě dokumentů s větším množstvím stránek může taková operace zabrat docela dost času aniž by ji bylo možné přerušit. |
Úprava perspektivy
U dokumentů skenovaných na plochém skeneru k deformaci vlivem perspektivy nedochází. Zato u dokumentů digitalizovaných pomocí fotoaparátu k ní dojde když osa objektivu fotoaparátu nebude vůči stránce kolmá ve všech směrech.
To lze opravit v prostředí gimpu pomocí nástroje Perspektiva.
- Nejprve si nastavte pomocná vodítka. Pro perspektivně deformované linie použijde dvě – bude se vám snadněji korigovat deformaci pomocí rohových táhel.
- Pak zvolte nástroj Perspektiva. Obraz se pak chová, jako by byl umístěn na pružné ploše, kterou pomocí táhel zobrazených v rozích natáhnete (či povolíte) tak, aby se deformace obrazu srovnala.
Je výhodné při snímání obrazu umístit na pozadí pomocnou mřížku. Usnadní to korekci perspektivy stránek, co neobsahují rovné linie, kterých by se dalo chytit. U dokumentů snímaných bez pomoci přítlačného skla, se může vyskytnout také deformace způsobená prohnutím stránky. I takový typ deformace lze zkorigovat, ovšem až po korekci chybné perspektivy! a to s pomocí transformační "klece".
U dokumentů snímaných bez pomoci přítlačného skla, se může vyskytnout také deformace způsobená prohnutím stránky. I takový typ deformace lze zkorigovat, ovšem až po korekci chybné perspektivy! a to s pomocí transformační "klece".
Funguje to podobně jako při úpravě perspektivy. Rozdíl je v tom, že si nejprve naklikáte kolem obrazu body – budoucí táhla transformační "klece" – a s jejich pomocí deformace srovnáte.
| Jde o výpočetně náročné operace, které vyžadují manuální zásah a komplikují automatizované zpracování. proto se snažte všem deformacím obrazu zabránit pokud možno již ve fázi kdy pořizujete originál. |
4, fáze - Postupné zpracování dalších vrstev (stránek)
Po natočení a usazení vrstvy, tak aby byl obsah mezi vodítky postupně pokračujeme ve zpracování dalších vrstev. Zpracované vrstvy postupně zamykáme a nastavujeme jako skryté. Přitom však nesmíme zapomínat označit jako aktivní nejvyšší viditelnou vrstvu s níž hodláme pracovat.
 Po zpracování všech vrstev můžeme nastavit další vodítka, jimiž vymezíme také vnější okraje stránek, podle kterých následně provedeme ořez.
Po zpracování všech vrstev můžeme nastavit další vodítka, jimiž vymezíme také vnější okraje stránek, podle kterých následně provedeme ořez.
5, fáze - Ořezání stránek
Vodítka podle kterých provedeme ořez by měla být zvolena tak, aby při tom nedošlo k nechtěnému oříznutí obsahu.
 Před oříznutím doporučuji mít skryté všechny vrstvy a postupně pak jednu po druhé zviditelnit a skrýt – a při tom překontrolovat, jestli vodítka nezasahují do stránky víc než je nutné.
Před oříznutím doporučuji mít skryté všechny vrstvy a postupně pak jednu po druhé zviditelnit a skrýt – a při tom překontrolovat, jestli vodítka nezasahují do stránky víc než je nutné.
 Po oříznutí dokumentu je vhodné vrstvy roztáhnout podle plátna a případně přesahující plochy dobarvit pomocí razítka, tak aby plocha pozadí byla pokud možno jednolitá, a zároveň vyretušovat skvrny které by mohly komplikovat OCR.
Po oříznutí dokumentu je vhodné vrstvy roztáhnout podle plátna a případně přesahující plochy dobarvit pomocí razítka, tak aby plocha pozadí byla pokud možno jednolitá, a zároveň vyretušovat skvrny které by mohly komplikovat OCR.
Takto upravený dokument je připraven pro další zpracování.
Korekce barev a čištění
Pro oddělení popředí (text) od pozadí se využívá černobílá maska, která určuje které obrazové body mají být součástí popředí (černé pixely) a které mají zůstat na pozadí. Tato maska se získá z originálního obrázku aplikací tzv. "prahu". Pixely světlejší než prahová hodnota zůstanou bílé a ty tmavší budou černé.
Na obrázku můžete vidět jak to dopadne u nekvalitně nasvícené stránky. V pravém horním rohu bude písmo tak nevýrazné, že ho bude mít OCR aplikace problém vůbec rozeznat, a naopak v levého dolním rohu, který je na originálu výrazně tmavší, ho nerozezná, protože se mu budou písmena slévat do jednolitých skvrn. U takové stránky se pak bude výsledek OCR pohybovat někde kolem 80%. Což znamená, že při korektuře textové vrstvy bude nutné napsat 20% textu znova. Nicméně existuje způsob, jak takovou předlohu výrazně vylepšit.
Logika vychází z následujících fakt:
- Plocha pozadí je větší než plocha, kterou zabírá text.
- Barva textu je vůči barvě pozadí silně kontrastní (má vyšší úroveň černé barvy).
- Pro rozpoznávání textu (OCR) jsou důležité pouze detaily popředí (textu), a tak lze vše co k němu nepatří zahodit
Bitmapový obrázek tvoří obrazové body které mají určitou RGB hodnotu, kterou lze popsat třemi čísly od 0 do 255. Pro zjednodušení si představte jeden řádek obrazových bodů jako následující sadu čísel:
111124211112421111
Kdyby to byla stránka bez textu, tak by byly barevné hodnoty obrazových bodů všechny stejné:
111111111111111111
Nás ale zajímají pouze barevné body popředí, a ty získáme tak, že od obrazových bodů s textem odečteme hodnotu obrazových bodů sady bez textu:
____131____131____
Výborně! Tak teď to zkusíme se sada hodnot obrazových bodů obrázku, který byl při skenování špatně nasvícený:
111124322223643344
Nejprve zkusíme odečíst barvy rovnoměrně nasvíceného papíru…
____13211112532233
Hm… tak to se předchozímu výsledku nepodobá ani náhodou, že? Tak to zkusíme razantněji…
_____21____1421122
No, opět výsledek nic moc. Zatím co na jedné straně se data začínají zvolna ztrácet, na té druhé je stále hodně šumu. Musíme na to tedy jinak.
Jak víme, pozadí tvoří většinu plochy. Pokud tedy nastavíme barvu obrazového bodu jako průměrnou hodnotu bodů v dostatečném rozsahu z levé i pravé strany, převládnou barvy pozadí a my tak získáme sadu, odpovídající špatně nasvícenému prázdnému papíru.
111111222222333344
…a po odečtení této sady na nás vyjukne opět sada obrazových bodů popředí:
____131____131____
Stačí tedy aplikovat na originální stránku filtr, který rozmaže barvu textové vrstvy tak, že převládne barva pozadí. A to pak odečíst.
Pokud pracujete v prostředí gimpu, tak si můžete vybrat, jestli k tomu použijete filtr "Median blur" ("Mediánové rozostření"), nebo "Despeckle" ("Vyčistit"). Výhodou je, že můžete prakticky ihned pomocí náhledu vidět jaký efekt budou mít vámi zvolené parametry. Klíčový je parametr Radius, který určuje kolik okolních pixelů bude bráno v úvahu při výpočtu výsledné barvy – čím bude větší, tím bude operace déle trvat.
Hodnota parametru Radius by měla být minimálně tak velká, jako je výška písma v pixelech na zpracovávaném dokumentu.
- Despeckle (Vyčistit)
- Je výpočetně poměrně náročná operace. Tento filtr se totiž normálně používá k odstranění jemného šumu. Při výpočtu barvy obrazového bodu se spočítá průměrná úroveň černé všech pixelů ve vzdálenosti vymezené Poloměrem (Radius) a pokud je vyšší než zvolená hodnota parametru Úroveň černé, zůstane hodnota obrazového bodu taková jaká je. V opačném případě se použije ta vypočtená.
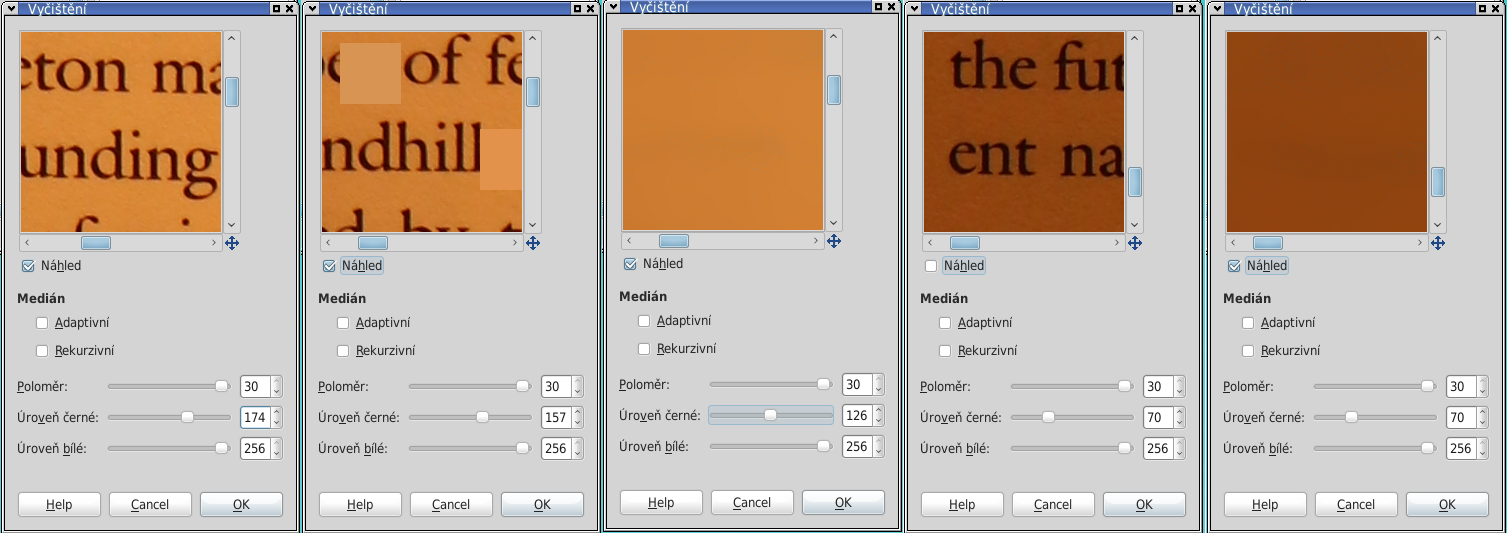 Optimální hodnotu pro nastavení Úrovně černé lze stanovit pomocí náhledu. Na obrázku lze vidět, jak to vypadá, při hraničním nastavení u světlejší oblasti stránky. Zatím co se při hodnotě 174 neděje nic, u hodnoty 157 se již objevují rozmazané oblasti. A při hodnotě 126 už je plocha náhledu rozostřena celá. Ovšem posuneme-li náhled do tmavší oblasti, zjistíme že by tato úroveň byla stále ještě moc vysoká, takže nakonec se výsledná hodnota pohybuje v tomto případě zhruba kolem 70.
Optimální hodnotu pro nastavení Úrovně černé lze stanovit pomocí náhledu. Na obrázku lze vidět, jak to vypadá, při hraničním nastavení u světlejší oblasti stránky. Zatím co se při hodnotě 174 neděje nic, u hodnoty 157 se již objevují rozmazané oblasti. A při hodnotě 126 už je plocha náhledu rozostřena celá. Ovšem posuneme-li náhled do tmavší oblasti, zjistíme že by tato úroveň byla stále ještě moc vysoká, takže nakonec se výsledná hodnota pohybuje v tomto případě zhruba kolem 70.
- Median blur
- Je filtr, který detaily neřeší. Spočítá průměrný medián všech barevných bodů v okolí vymezeném nastavením Radiusu (Poloměru) tuto hodnotu nastaví barevnému bodu. Čím větší radius, tím větší míra rozostření, tím více počítání. Na druhou stranu v tomto případě odpadá rozhodovací proces, takže je tento filtr o něco rychlejší.
Protože nevyžaduje žádné sofistikované nastavení (stačí vědět jak zhruba velké písmo v pixelech na stránce) je tento filtr vhodný je hromadnému zpracování skenů na příkazové řádce, pomocí nástrojů z NetPBM. Následující schéma demonstruje jak vydolovat text z obrázku na příkazové řádce:

- Nástroj pgmmedian pracuje pouze s obrázky ve stupních šedi, proto musíme nejprve obrázek pomocí ppmtorgb3 rozebrat na jednotlivé barevné kanály
- Každý z nich se pak pak přes pgmmedian samostatně rozmaže…
- …a rgb3toppm z nich složí opět barevný obrázek – ten však bude rozmazaný tak, že bude vypadat jako pozadí původního obrázku bez textu.
- Když potom pomocí utility pamarith toto pozadí oddělíme (divide) od původního obrázku, vyjukne víceméně čisté popředí s textem.
 Protože aplikace jednotlivých operací krok po kroku, by byla poněku nepraktická, demonstruje následující kód jednoduchý shellový skript kterým se připraví obrázek pro oddělení barevného pozadí dle zadaných parametrů. Číselnou hodnotou radiusu, lze upravit jakým způsobem bude stránka rozostřena.
Protože aplikace jednotlivých operací krok po kroku, by byla poněku nepraktická, demonstruje následující kód jednoduchý shellový skript kterým se připraví obrázek pro oddělení barevného pozadí dle zadaných parametrů. Číselnou hodnotou radiusu, lze upravit jakým způsobem bude stránka rozostřena.
Jsou-li obě hodnoty stejné, bude zpracovávaná plocha kruhová. V případě že bude některá z nich menší (nebo větší), bude plocha oválná. Pro rozmazání textu na řádce by mělo první číslo odpovídat šířce znaku v pixelech a druhé výšce řádku – rovněž v pixelech.
user@stroj:~$ ./medianblur.sh vstupni.pnm 55,55 > pozadi.pnm
user@stroj:~$ pamarith -divide vstupni.pnm pozadi.pnm > popredi.pnm
user@stroj:~$ cat ./medianblur.sh
#!/bin/bash
NAME="medianblur"
ORIG=$1
RADIUS=(${2/,/ })
# TYPE může být také select, ale operace trvá delší dobu
TYPE="histogram_sort"
PPMTORGB3=$(command -v ppmtorgb3)
[ ! -x "${PPMTORGB3}" ] && exit 2
PGMMEDIAN=$(command -v pgmmedian)
[ ! -x "${PGMMEDIAN}" ] && exit 3
RGB3TOPPM=$(command -v rgb3toppm)
[ ! -x "${RGB3TOPPM}" ] && exit 4
PAMARITH=$(command -v pamarith)
[ ! -x "${PAMARITH}" ] && exit 5
trap '''CHYBA=$? ;
case $CHYBA in
2|3|4|5) echo "Doinstalovat netpbm"
;;
esac
[ $NORMDIR ] || rm -rf -- "$TEMPDIR"
exit $CHYBA
''' EXIT
TEMPDIR=$(mktemp -d -p /tmp ${NAME}-XXX) || exit 1
median () {
${PGMMEDIAN} -width=${RADIUS[0]} -height=${RADIUS[1]} -type ${TYPE} $1
}
TEMPFILE=$(tempfile -d ${TEMPDIR} -s .ppm)
cp ${ORIG} ${TEMPFILE}
pushd ${TEMPDIR} &>/dev/null
${PPMTORGB3} ${TEMPFILE} && median ${TEMPFILE//.ppm/.red} > ${TEMPFILE//.ppm/med.red} && median ${TEMPFILE//.ppm/.grn} > ${TEMPFILE//.ppm/med.grn} && median ${TEMPFILE//.ppm/.blu} > ${TEMPFILE//.ppm/med.blu}
${RGB3TOPPM} ${TEMPFILE//.ppm/med.red} ${TEMPFILE//.ppm/med.grn} ${TEMPFILE//.ppm/med.blu}
popd &>/dev/null
Text při tom ale může mírně ztratit na barevné intenzitě a na pozadí výsledného obrázku mohou zůstat nevýrazné barevné artefakty. Proto aplikujeme další filtry:
- Grain merge
- Posílí barvu textu
- Linear burn
- Zahodí barevné artefakty pozadí
Můžeme ale také využít vytvořenou černobílou masku, kterou použijme v kombinaci z rozmazávacím filtrem „Rozostření objektivu” (Lens blus), a vytvořit vstupní obrázek s rozmazaným pozadím. Což by mělo vést k eliminaci artefaktů ještě před oddělením barevného pozadí.
- O rozmazávacích filtrech využitelných v rámci open source bitmapového editoru GIMP, jejich použití a parametrech podrobněji píšu na strínce GIMP a rozmazávací filtry.
- O černobílé masce a jejím vlivu při použití k vytvoření DjVu souboru, se podrobněji píše ma v článku GIMP a vytvoření masky